
Dianggarkan bahawa menjelang 2030, skala industri data negara saya akan mencapai 7.5 trilion yuan.
alt = ""/> src = "http://www.china-news-online.com/pic/2025-05-18/1kqbamcvbsw.png" alt = "" //
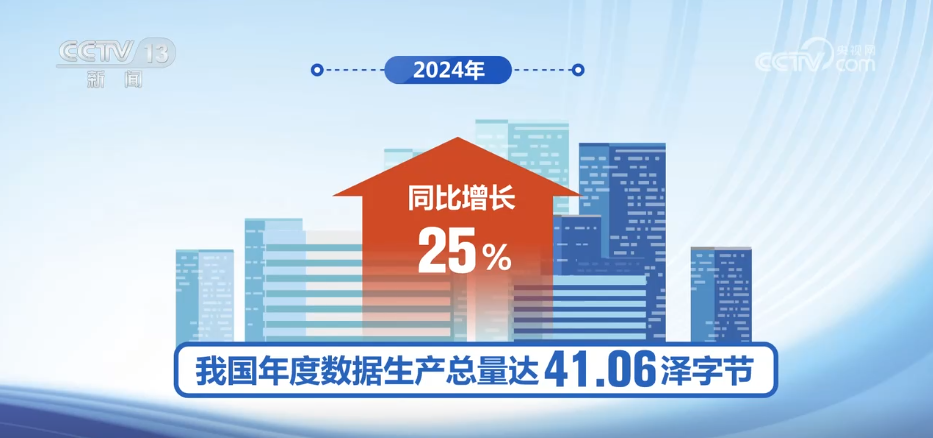
Pada tahun 2024, bilangan platform terbuka data awam tempatan di atau di atas peringkat perbandaran di seluruh negara meningkat sebanyak 7.5%, bilangan data terbuka meningkat sebanyak 7.1%, dan bilangan set data berkualiti tinggi meningkat sebanyak 27.4%tahun ke tahun. Dari segi penyepaduan elemen data dan industri, negara mempercepat halangan pembukaan kepada perkongsian data awam, mempromosikan integrasi data awam dan data perusahaan yang mendalam, dan mengaktifkan "data tidur" yang besar.Membina set data berkualiti tinggi untuk mempercepatkan perkembangan kecerdasan buatan
Set data berkualiti tinggi bukan sahaja menjadi landasan lonjakan dalam prestasi model kecerdasan buatan, tetapi juga membentuk semula keseluruhan rantaian industri dari penyelidikan dan pembangunan teknologi kepada pelaksanaan komersial. Jadi bagaimana set data berkualiti tinggi dibina?

Personel teknikal memberitahu pemberita bahawa membina set data model yang besar terutamanya termasuk pautan teras seperti pengumpulan data, pembersihan data, anotasi data, dan penilaian kualiti. Setiap pautan perlu menjalankan penyelidikan dan pembangunan teknikal yang disasarkan dan penyesuaian berdasarkan ciri-ciri kepelbagaian besar, kepelbagaian yang mencukupi, dan sifat menegak yang kuat dalam industri.
Anotasi dan pembersihan data adalah pautan utama dalam pembinaan set data berkualiti tinggi. Anotasi data mengajar kecerdasan buatan untuk "mengiktiraf dunia" dengan "pelabelan" (seperti pelabelan "kucing" dan "anjing" untuk foto). Data tidak berlabel adalah seperti buku teks yang dihiasi, mengakibatkan ketidakupayaan kecerdasan buatan untuk belajar dengan berkesan; Pembersihan data membersihkan data dengan membuang pendua dan membetulkan kesilapan, dan data kacau akan secara langsung mempengaruhi keberkesanan latihan kecerdasan buatan.
Nilai output industri pelabelan data negara saya melebihi 8 bilion
Ia dapat dilihat bahawa pelabelan data adalah pautan utama dalam pembinaan set data berkualiti tinggi. Jadi apakah pembangunan industri berkaitan negara saya? Laporan Penyelidikan Set Data Berkualiti Tinggi "2025 yang dikeluarkan oleh Persidangan Pembangunan Keselamatan Data 2025 menunjukkan bahawa dengan lelaran kecerdasan buatan dan teknologi model berskala besar, nilai output industri pelabelan data negara saya telah melebihi 8 bilion yuan, dan pembinaan data berkualiti tinggi telah memasuki tahap baru skala besar dan pembangunan standard.
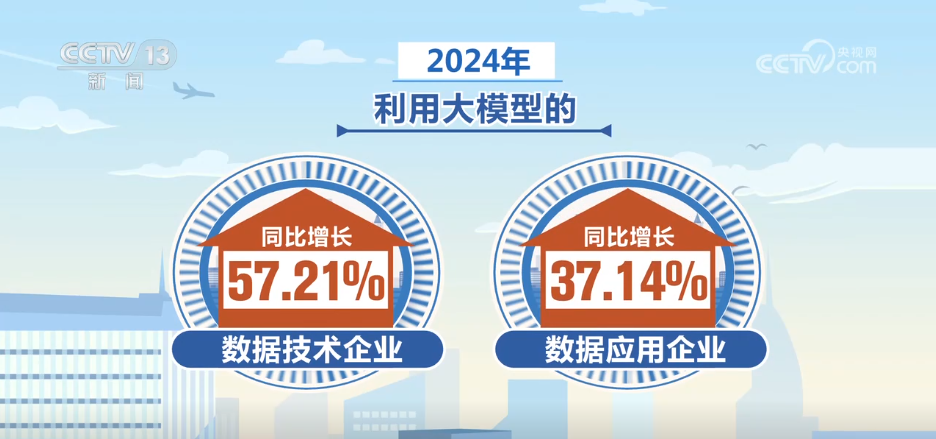

The report shows that my country is currently accelerating the innovation and development of high-quality data sets, Tetapi ia masih menghadapi masalah seperti stok data kecil, pengeluaran yang rendah, kualiti data yang tidak sekata, kekurangan panduan data bernilai tinggi arus perdana, dan kecekapan penggunaan data yang rendah.


