CCTV News: Vào ngày 17 tháng 5, phóng viên đã học được từ Hội nghị phát triển bảo mật dữ liệu năm 2025 rằng đất nước tôi sẽ trau dồi và mở rộng một số doanh nghiệp ngược dòng và hạ nguồn trong chuỗi ngành công nghiệp nhân tố dữ liệu. Ước tính vào năm 2030, quy mô của ngành công nghiệp dữ liệu của đất nước tôi sẽ đạt tới 7,5 nghìn tỷ nhân dân tệ.
Liu Liehong, giám đốc của Cơ quan Quản lý Dữ liệu Quốc gia, cho biết ông hiện đang lên kế hoạch xây dựng một hệ thống cơ sở hạ tầng dữ liệu theo chiều dọc, dọc và phối hợp và cơ bản xây dựng cấu trúc chính của cơ sở hạ tầng dữ liệu quốc gia vào năm 2029. src = "http://www.china-news-online.com/pic/2025-05-18/1kqbamcvbsw.png" alt = "" //
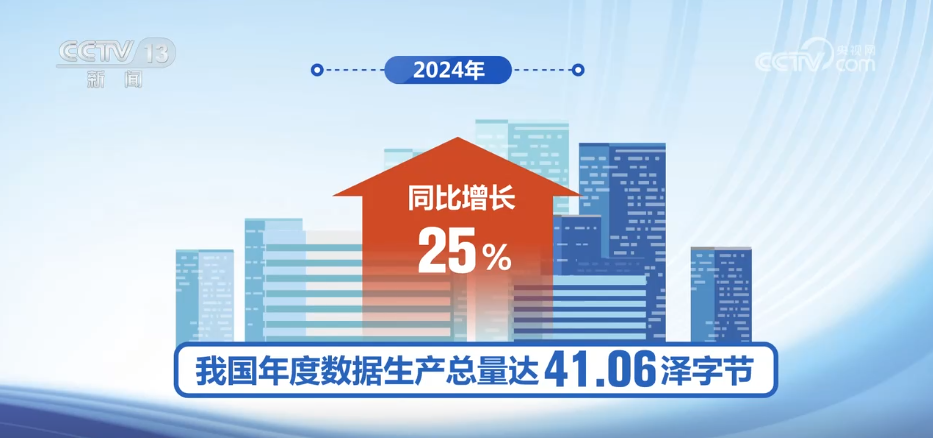
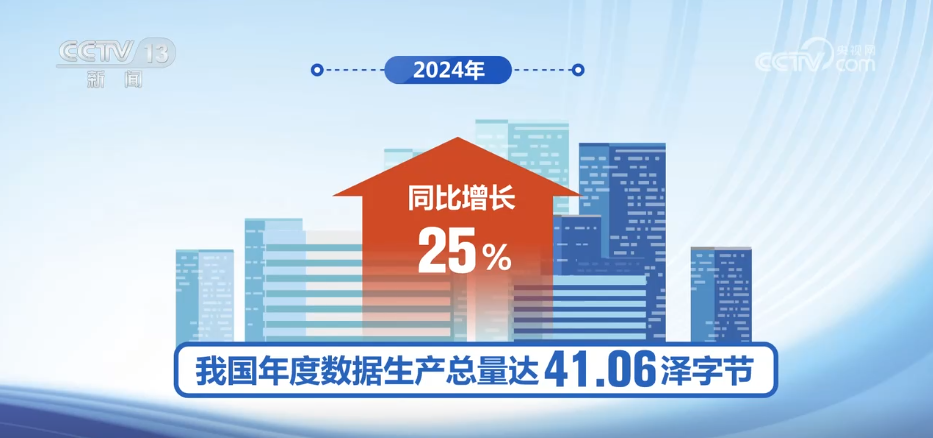
Chia sẻ dữ liệu công khai đã trở thành một bước đột phá quan trọng trong việc tiếp thị các yếu tố dữ liệu. Vào năm 2024, số lượng dữ liệu công cộng địa phương mở các nền tảng mở ở cấp hoặc trên cấp thành phố trên toàn quốc tăng 7,5%, số lượng dữ liệu mở tăng 7,1%và số lượng dữ liệu chất lượng cao tăng 27,4%so với năm trước. Về việc tích hợp các yếu tố và ngành công nghiệp dữ liệu, quốc gia này đang tăng tốc các rào cản mở ra đối với việc chia sẻ dữ liệu công cộng, thúc đẩy sự tích hợp sâu của dữ liệu công cộng và dữ liệu doanh nghiệp và kích hoạt "dữ liệu ngủ" khổng lồ.
Xây dựng các bộ dữ liệu chất lượng cao để tăng tốc sự phát triển của trí tuệ nhân tạo
Hiện tại, dữ liệu đã vượt qua các yếu tố sản xuất truyền thống và trở thành động lực cốt lõi cho các bước đột phá trong công nghệ trí tuệ nhân tạo và chuyển đổi công nghiệp. Các bộ dữ liệu chất lượng cao không chỉ là nền tảng của bước nhảy vọt trong hiệu suất mô hình trí tuệ nhân tạo, mà còn định hình lại toàn bộ chuỗi công nghiệp từ nghiên cứu và phát triển công nghệ đến thực hiện thương mại. Vậy các bộ dữ liệu chất lượng cao được xây dựng như thế nào?
Nhân viên kỹ thuật nói với các phóng viên rằng việc xây dựng các bộ dữ liệu mô hình lớn chủ yếu bao gồm các liên kết cốt lõi như thu thập dữ liệu, làm sạch dữ liệu, chú thích dữ liệu và đánh giá chất lượng. Mỗi liên kết cần thực hiện nghiên cứu và phát triển kỹ thuật và thích ứng được nhắm mục tiêu dựa trên các đặc điểm của quy mô lớn, đa dạng đủ và các thuộc tính thẳng đứng mạnh mẽ của ngành.
Chú thích và làm sạch dữ liệu là các liên kết chính trong việc xây dựng các bộ dữ liệu chất lượng cao. Chú thích dữ liệu dạy trí tuệ nhân tạo "nhận thức thế giới" bằng cách "dán nhãn" (chẳng hạn như dán nhãn "mèo" và "chó" cho ảnh). Dữ liệu không được dán nhãn giống như sách giáo khoa bị cắt xén, dẫn đến việc không có trí tuệ nhân tạo để học hiệu quả; Làm sạch dữ liệu thanh lọc dữ liệu bằng cách loại bỏ các bản sao và sửa lỗi, và dữ liệu hỗn loạn sẽ ảnh hưởng trực tiếp đến hiệu quả của đào tạo trí tuệ nhân tạo.
Giá trị đầu ra của ngành ghi nhãn dữ liệu của quốc gia tôi vượt quá 8 tỷ
Có thể thấy rằng ghi nhãn dữ liệu là một liên kết chính trong việc xây dựng các bộ dữ liệu chất lượng cao. Vậy sự phát triển của các ngành công nghiệp liên quan của đất nước tôi là gì? "Báo cáo nghiên cứu bộ dữ liệu chất lượng cao 2025" được công bố bởi Hội nghị phát triển bảo mật dữ liệu năm 2025 cho thấy với sự lặp lại của trí tuệ nhân tạo và công nghệ mô hình quy mô lớn, giá trị đầu ra của ngành ghi nhãn dữ liệu của đất nước tôi đã vượt quá 8 tỷ nhân dân tệ và việc xây dựng dữ liệu chất lượng cao đã bước vào giai đoạn phát triển quy mô lớn và quy mô lớn.