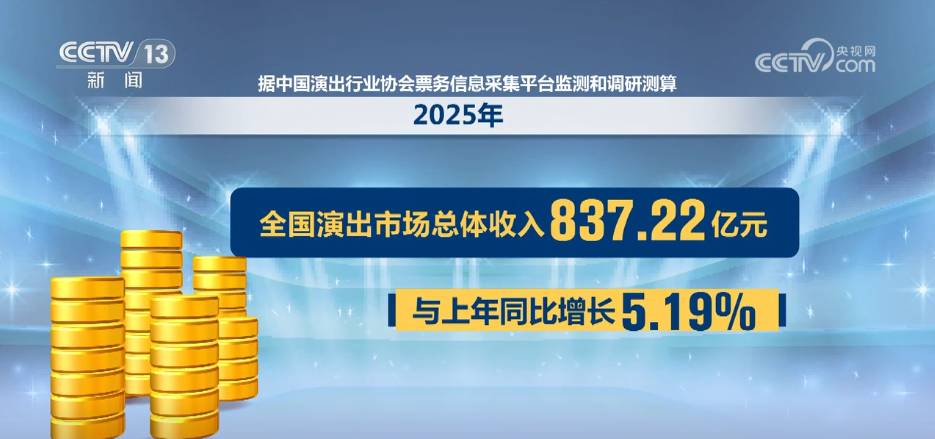
17日,记者从2025数据安全发展大会上获悉,我国将培育壮大一批数据要素产业链上下游企业,预计到2030年,我国数据产业规模将达到7.5万亿元。
公共数据开放共享
激活海量“沉睡数据”
作为全球首个将数据纳入生产要素的国家,我国已初步构建起门类齐全的数据产业链。数据显示,2024年我国年度数据生产总量达41.06泽字节,同比增长25%。
截至目前,我国数据领域相关企业超19万家,数据产业规模超2万亿元。按照20%以上的年均增长率测算,2030年我国数据产业规模将达7.5万亿元。

国家数据局局长 刘烈宏:当前我们正谋划构建横向联通、纵向贯通、协调有力的数据基础设施体系,到2029年要基本建成国家数据基础设施主体结构。
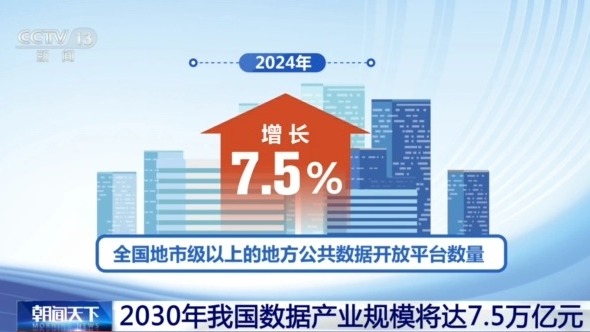
公共数据开放共享成为数据要素市场化的重要突破口。2024年全国地市级以上的地方公共数据开放平台数量增长7.5%,开放数据量增长7.1%,高质量数据集数量同比增长27.4%。
在数据要素与产业融合方面,国家正加快打通公共数据共享开放壁垒,推动公共数据与企业数据深度融合,激活海量“沉睡数据”。
构建高质量数据集
加速人工智能发展
眼下,数据已超越传统生产要素,成为驱动人工智能技术突破与产业变革的核心动力。高质量数据集不仅是人工智能模型性能跃升的基石,更重塑了从技术研发到商业落地的全产业链条。那高质量数据集是如何构建的?
在浙江温州,作为全国数据要素市场化改革的“试验田”,这里构建了一套数据安全与合规体系,保障数据要素规模化流动,形成数据交易生态圈,让更多数据“活了起来”。

浙江省温州市数据局副局长 金传拉:打造了469款“实用、好用、安全”的数据产品,在医疗、交通、低空经济等领域建设了一批高质量数据集。
技术人员告诉记者,构建大模型数据集主要包含数据采集、数据清洗、数据标注、质量评估等核心环节。各环节需要根据大模型数据集的规模大、多样性足、行业垂直属性强等特点进行针对性技术研发和适配。

北京大学计算机学院教授 黄铁军:文本类的数据,文献、图书、论文、研究报告,这些数据大部分已经用了。未来还是需要更多非文本的,比如说图像、视频、各种传感器的,这些数据也是大模型学习的重要来源。
数据标注与清洗是高质量数据集建设的关键环节。
数据标注通过“贴标签”,教会人工智能“认知世界”,未经标注的数据如同乱码教材,导致人工智能无法有效学习;
数据清洗则通过剔除重复、修正错误等操作净化数据,混乱数据将直接影响人工智能训练效果。
赛迪研究院副总工程师 刘权:当数据覆盖足够广泛的场景并经过专业标注时,AI模型才能突破“实验室精度”,真正具备产业落地的能力,带动数字经济发展。
我国数据标注产业产值超80亿元
在2025数据安全发展大会发布的《2025高质量数据集研究报告》显示,随着人工智能、大模型技术迭代,我国数据标注产业产值已突破80亿元,高质量数据建设进入规模化、规范化发展新阶段。
2024年,我国开发或应用人工智能的企业数量同比增长36%,高质量数据集数量同比增长27.4%,有力支撑人工智能训练和应用。利用大模型的数据技术企业和数据应用企业同比分别增长57.21%、37.14%。
赛迪研究院副院长 刘文强:我们大模型的参数已经达到了几千亿级别。推进全国七个数据标注基地建设,构建医疗、工业、教育等领域的335个高质量数据集,标注总规模达到1.7万亿TB,支撑了121个国产大模型的研发。
报告显示,当前我国正加速推动高质量数据集创新发展,但是仍然面临数据存量小产量低、数据集质量良莠不齐、缺乏主流高价值数据引领、数据利用效率低等问题。

赛迪研究院副总工程师 刘权:做好数据源头管控,确保数据来源的可靠性、完整性。加强数据隐私与安全保障,推动数据集安全评估能力建设。
(总台央视记者 王世玉 张伟 唐志坚 张延 韩栋)