El 17, el reportero aprendió de la Conferencia de Desarrollo de Seguridad de Datos de 2025 que mi país cultivará y expandirá una serie de empresas aguas arriba y aguas abajo en la cadena de la industria del factor de datos. Se estima que para 2030, la escala de la industria de datos de mi país alcanzará 7.5 billones de yuanes.
Compartir abiertos de datos públicos
Active "datos de sueño" masivos
Como el primer país del mundo en incluir datos en factores de producción, mi país inicialmente ha construido una cadena de la industria de datos completa. Los datos muestran que la producción de datos anual de mi país en 2024 alcanzó 41.06 bytes ZET, un aumento interanual del 25%.
A partir de ahora, hay más de 190,000 empresas relacionadas en el campo de datos en mi país, y la escala de la industria de datos supera los 2 billones de yuanes. Based on the annual growth rate of more than 20%, the scale of my country's data industry will reach 7.5 trillion yuan in 2030.

Director de la Administración Nacional de Datos Liu Liehong: en la actualidad, estamos planeando construir una construcción de infraestructura de datos conectada, conectada verticalmente y coordinada horizontalmente, y básicamente construir la estructura principal de la infraestructura de datos nacional para 2029.
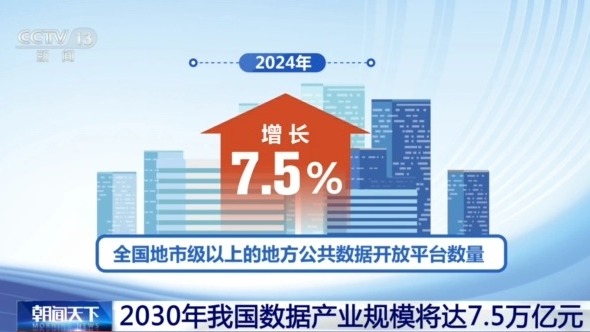
El intercambio abierto de datos públicos se ha convertido en un importante ruptura en la comercialización de los elementos de datos. En 2024, el número de plataformas abiertas de datos públicos locales en el nivel municipal o por encima de todo el país aumentó en un 7,5%, el número de datos abiertos aumentó en un 7,1%y el número de conjuntos de datos de alta calidad aumentó en un 27,4%interanual.
En términos de la integración de elementos de datos e industrias, el país está acelerando las barreras de apertura para el intercambio de datos públicos, promoviendo la profunda integración de datos públicos y datos empresariales, y activa un "datos de sueño" masivos.
Construir conjuntos de datos de alta calidad. Los conjuntos de datos de alta calidad no son solo la piedra angular del salto en el rendimiento del modelo de inteligencia artificial, sino que también remodelan toda la cadena industrial desde la investigación y el desarrollo tecnológico hasta la implementación comercial. Entonces, ¿cómo se construyen los conjuntos de datos de alta calidad?
En Wenzhou, Zhejiang, como un "campo de prueba" para la reforma de elementos de datos orientados al mercado nacional, se ha construido un sistema de seguridad y cumplimiento de datos aquí para garantizar el flujo a gran escala de elementos de datos de datos de datos, y hacer más datos en vivo ".

jin chuanla, director subputado de los datos de los datos, burohuhuhuhuhuhuhuhuhuhuhuhuhuhuhuhuhuhuhuhuhuhuhuhuhuhuhuhuhuhuhuhuhuhuhuhuhuhuhuhuhu. Provincia de Zhejiang: se han creado productos de datos "prácticos, fáciles de usar y seguros", y se han construido un lote de conjuntos de datos de alta calidad en los campos de atención médica, transporte, economía de baja altitud, etc.
El personal técnico dijo a los reporteros que construyen grandes conjuntos de datos de modelos que incluyen los enlaces principalmente de los enlaces como la recopilación de datos, la limpieza de datos, la anotación de datos y la anotación de la calidad y la evaluación de la calidad de la calidad. Cada enlace necesita llevar a cabo la investigación y el desarrollo de la tecnología específica y la adaptación basada en las características de la diversidad a gran escala, suficiente diversidad y fuertes atributos verticales de la industria.

Profesor Huang Tiejun, School of Computer Science, Peking University, Peking, la mayoría de los tipos de textos, literar Se han utilizado libros, documentos, informes de investigación. En el futuro, todavía se necesitan más cosas no textuales, como imágenes, videos y varios sensores. Estos datos también son una fuente importante de aprendizaje de modelos a gran escala.
La anotación y la limpieza de datos son enlaces clave en la construcción de conjuntos de datos de alta calidad.
La anotación de datos enseña inteligencia artificial a "conocer el mundo" a través de "etiquetado". Los datos no etiquetados son como los libros de texto confusos, lo que resulta en que la inteligencia artificial no pueda aprender de manera efectiva;
La limpieza de datos purifica los datos al eliminar los duplicados y la corrección de errores, y los datos caóticos afectarán directamente la efectividad de la capacitación de inteligencia artificial.
liu quan, ingeniero jefe subterráneo de cydie de investigación cydie de investigación: solo los datos de los datos " escenario y es un marcado profesionalmente el modelo de IA se atraviesa la "precisión del laboratorio", realmente tiene la capacidad de implementar industrias e impulsar el desarrollo de la economía digital.
El valor de salida de la industria de etiquetado de datos de mi país supera los 8 mil millones de yuanes
El "Informe de investigación de datos de datos de alta calidad de 2025" publicado en la Conferencia de Desarrollo de Seguridad de Datos de 2025 muestra que con la iteración de la inteligencia artificial y la tecnología de modelos a gran escala, el valor de salida de la industria de la etiqueta de datos de mi país ha superado los 8 billetes y la construcción de la construcción de la construcción de la construcción de la construcción de la construcción de la construcción de la construcción de la construcción de la construcción de la construcción de la construcción de la construcción de la construcción de la construcción de la construcción de la construcción de la construcción de los datos de la gran etapa de las altas etapas de la construcción de la gran etapa de la construcción de la construcción de la construcción de la construcción de la mayor etapa de la construcción de la construcción de la construcción de la construcción de la construcción de la construcción de la construcción de la construcción de la construcción de 8. Desarrollo a gran escala y estandarizado.
En 2024, el número de empresas que desarrollan o aplican inteligencia artificial en mi país aumentó un 36% interanual, y el número de conjuntos de datos de alta calidad aumentó en un 27.4% anual, apoyando fuertemente la capacitación y aplicación de inteligencia artificial. Las empresas de tecnología de datos que utilizan modelos grandes y compañías de aplicaciones de datos aumentaron en un 57.21% y 37.14% interanual respectivamente.
liu wenqiang, vicepresidente de cydie de investigación: el instituto de los parámetros de los parámetros: el instituto de los parámetros de los parámetros de los parámetros de los parámetros de los parámetros: los parámetros de los parámetros de los parámetros de los parámetros de los parámetros de los parámetros de los parámetros: los parámetros de los parámetros de los parámetros: el Instituto de los Parámetros de Cydie: el Instituto de los Parámetros de Cydie alcanzó cientos de miles de millones de niveles. Promueva la construcción de siete bases de etiquetado de datos en todo el país, construya 335 conjuntos de datos de alta calidad en los campos de atención médica, industria, educación, etc., con una escala de marcado total de 1.7 billones de TB, que respalda la investigación y el desarrollo de 121 modelos grandes nacionales.
El informe muestra que mi país está acelerando actualmente la innovación y el desarrollo de conjuntos de datos de alta calidad, pero aún enfrenta problemas como pequeñas existencias de datos y bajas salidas, calidad desigual de conjuntos de datos, falta de guía de datos de alto valor convencional y baja eficiencia de utilización de datos.

liu quan, ingeniero jefe de investigaciones cydie de cydie de cydie en el instituto de la investigación de los datos de los datos. confiabilidad e integridad de fuentes de datos. Fortalecer la privacidad de los datos y las garantías de seguridad y promover la construcción de capacidades de evaluación de seguridad del conjunto de datos.
(Reporteros de CCTV Wang Shiyu, Zhang Wei, Tang Zhijian, Zhang Yan, Han Dong)



